4. バイナリの構築とマッチング¶
R12Bからコードが改善され、バイナリを作成したりマッチングのコードを書くための普段もっとも使う書き方に関して、以前のバージョンよりもかなり高速化されました。
バイナリを作成する時には以下のようにシンプルに書くことができます。
R12Bでの推奨 / 以前のバージョンで非推奨:
my_list_to_binary(List) ->
my_list_to_binary(List, <<>>).
my_list_to_binary([H|T], Acc) ->
my_list_to_binary(T, <<Acc/binary,H>>);
my_list_to_binary([], Acc) ->
Acc.
R12B以前のリリースでは、Accは繰り返し [1] ごとにコピーされていました。R12Bからは最初の繰り返し時だけコピーされ、最終的なコピー済みのバイナリを格納する追加領域が確保されます。次以降の繰り返しからは、Hは追加領域に書かれていきます。追加領域を使い果たしてしまったときは、再割り当てが行われ、領域が増やされます。
| [1] | (訳注)この関数は再帰呼び出しですが、末尾再帰の最適化により繰り返しとなると思われます。 |
追加領域の割り当て、あるいは再割り当ては、既存のバイナリデータのサイズの2倍、もしくは256バイトのどちらか大きな方のサイズにて行われます。
以下のような、バイナリのマッチのもっとも自然な書き方が、最速の実装になります。
推奨(R12B以降):
my_binary_to_list(<<H,T/binary>>) ->
[H|my_binary_to_list(T)];
my_binary_to_list(<<>>) -> [].
4.1. バイナリはどのように実装されているのか?¶
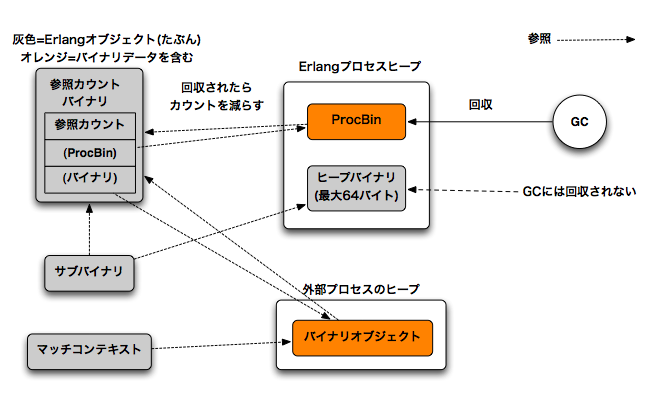
バイナリの実装(szkttyさん作成)
内部的には、バイナリも、ビット文字列も同じ方法で実装されています。両方ともエミュレータソースコードで呼ばれているように、このセクションでは、両方ともバイナリと呼ぶことにします。
内部では4種類のバイナリオブジェクトがあります。そのうちの2つが、バイナリデータを格納するコンテナで、残りの二つは、バイナリデータの一部を表すリファレンスです。
バイナリのコンテナはrefcバイナリ、ヒープバイナリと呼ばれています。refcはリファレンスカウントされたバイナリ(reference-counted binaries)の略です。
refcバイナリは二つの部分で構成されています。ひとつはProcBinと呼ばれるプロセスヒープ上に格納されているオブジェクトです。もうひとつはすべてのプロセスヒープ以外の領域に格納されているバイナリオブジェクトになります。
バイナリオブジェクトは他のプロセスのProcBinからも参照することができます。いくつものプロセス上の複数のProcBinから参照することもできます。オブジェクトには、参照数を記憶しておくためのリファレンスカウンタが内蔵されており、最後の参照がなくなった時点で削除されます。
ガーベジコレクタから監視できるように、ProcBinオブジェクト自体がリンクリストとして実装されていて、プロセスの中のすべてのProcBinオブジェクトは連結されています。そして、ProcBinがなくなったら参照カウントが減らされます。
ヒープバイナリというのは64バイトまでの小さなバイナリのための仕組みです。これはプロセスのヒープに直接格納されます。プロセスがガベージコレクタに回収されたり、ヒープバイナリをメッセージとして送ったりする時には、ヒープバイナリのコピーが作成されます。ヒープバイナリはガベージコレクタから特別扱いはされません。
リファレンスオブジェクトは2つのタイプがあり、それぞれ、refcバイナリ、ヒープバイナリの一部を表します。これらは、サブバイナリ、マッチコンテキストと呼ばれます。
サブバイナリはsplit_binary/2を作って作成することができます。また、バイナリパターンでマッチさせて作ることもできます。サブバイナリは他のバイナリの一部を示す参照です。ここで言う他のバイナリというのはrefcかヒープバイナリで、他のサブバイナリの一部を参照することはできません。このように、実際にバイナリデータをコピーすることはないので、バイナリをマッチさせて一部を抜きだすという操作は比較的コストの安い操作だということが分かります。
マッチコンテキストは、サブバイナリと似ていますが、これはバイナリのマッチに最適化したものになります。実際には、バイナリデータへの直接のポインタを持ちます。バイナリに対してそれぞれのフィールドにマッチするたびに、マッチコンテキストの位置はインクリメントされます。
R11Bまではマッチコンテキストはバイナリマッチ操作にしか使用できませんでした。
R12B以降は、コンパイラはできるだけサブバイナリを作成するのを避けて、新しい マッチコンテキストを作成しようとします。(訳注:同じことを3回言っている?)
この最適化が行えるのは、マッチコンテキストが明らかに共有されることはない、ということが分かっているときに限られます。もし、これが共有されてしまうと、Erlangの関数型の特性(参照透明とも言われる)が壊れてしまうでしょう。
4.2. バイナリの作成¶
R12Bでは以下のようにして、バイナリ、ビット文字列に対して追加すると、ランタイムシステムが特別な最適化を行います。:
<<Binary/binary, ...>>
<<Binary/bitstring, ...>>
コンパイラではなく、ランタイムシステムが最適化を行っているため、状況によっては最適化がうまく働かないことがあります。
最適化がどのように行われるかを説明するために、以下のコードを使って見ていきましょう。:
Bin0 = <<0>>, %% 1
Bin1 = <<Bin0/binary,1,2,3>>, %% 2
Bin2 = <<Bin1/binary,4,5,6>>, %% 3
Bin3 = <<Bin2/binary,7,8,9>>, %% 4
Bin4 = <<Bin1/binary,17>>, %% 5 !!!
{Bin4,Bin3} %% 6
一行ずつ見ていきます。
最初の行(%%1とコメントされている)は、ヒープバイナリをBin0という変数に割り当てています。
2行目は、追加の操作になります。Bin0に追加の操作が行われていない間(訳注:notいらなくね?)は、新しいrefcバイナリが作成され、Bin0の内容がそれの中にコピーされます。refcバイナリの一部のProcBinは、バイナリオブジェクトが追加のメモリ領域の割り当てを行ったら、バイナリの中に格納されているデータサイズを、自分のサイズ属性として保持します。バイナリオブジェクトのサイズは、Bin0の2倍か、もしくは256のどちらか大きいほうになります。この場合には256になります。
3行目はもっと興味深いことが発生します。Bin1が追加の操作で使用されますが、Bin1は後ろのほうに255バイトの未使用のストレージがあります。そのため、3つの新しいバイナリ情報がここに格納されます。
4行目も同様です。252バイトの秋領域があるため、追加の3バイト分のデータが問題なく格納されます。
しかし、5行目では面白いことが発生します。ここで注意して欲しいのは、前の行のBin3ではなく、前に出てきたBin1に対して追加を行っている点です。私たちはBin4には <<0,1,2,3,17>>という値が割り当てられるのを期待します。また、Bin3に関しても、<< 0,1,2,3,4,5,6,7,8,9>>というもとの値が残ることを期待しています。明らかに、実行時システムは17というバイトをバイナリに書き込むことはできません。というのは、Bin3の値が<<0,1,2,3,4,17,6,7,8,9>>と変化してしまうからです。
何が起きているのでしょうか?
ランタイムは、Bin1が以前行われた追加操作の結果であるということを知ります。直前の追加操作という情報からではありません。そこで、ランタイムシステムはBin1の内容を新しいバイナリと、予約済の追加の保存領域などにコピーします。ここでは、ランタイムシステムがどのようにしてBin1に対して書き込むことができるかどうか知ることができるのか、ということについては説明しません。これは好奇心旺盛な読者のためのエクササイズとしておきます。erl_bits.cなどのエミュレータのコードを読むと、どのようにして行っているかを知ることができます。
4.2.1. 強制コピーを行う状況¶
バイナリの追加操作の最適化には、ひとつのProcBinと、バイナリに対するひとつのProcBinへの参照が必要となります。理由としては、バイナリオブジェクトは追加操作時に動かしたり、再割り当てを行うことがあり、それが発生してしまうと、ProcBinの中のポインタ値までアップデートしなければならなくなるからです。もしバイナリオブジェクトに対して、2つ以上のProcBinが参照していたとすると、すべてのProcBinを見つけてアップデートすることはできません。
そのため、バイナリへの特定操作はチェックされて、追加の操作が行われる時に、強制的にバイナリをコピーするかどうか、決定されます。ほとんどのケースでは、バイナリオブジェクトが追加のスペースの割り当てを要求するのと同時に、サイズが縮められます。
以下のようにバイナリに追加する時:
Bin = <<Bin0,...>>
バイナリが直前に行われた追加操作から戻ってきたときだけ、コストの安い追加操作がサポートされます。上記のようなコード片の場合、Binに対して追加する操作が行われると、コストの安い方法が使用されます。これに対して、Bin0に対して追加が行われると、強制的に新しいバイナリオブジェクトが作成され、Bin0の内容がコピーされることになります。
もしバイナリがメッセージとしてプロセスやポートから送信される場合には、バイナリは縮められ、あらゆる追加操作に対して、新しいバイナリオブジェクトへのデータのコピーが強制的に行われるようになります。以下のようなコード片があったとします。:
Bin1 = <<Bin0,...>>,
PortOrPid ! Bin1,
Bin = <<Bin1,...>> %% Bin1はコピーされる
Bin1は3行目でコピーされるます。
同様に、etsテーブルにバイナリを挿入したり、erlang:port_command/2を使用してポートにバイナリを送信しても、同じことが発生します。
バイナリのマッチングについても同様に、バイナリの縮小と、次に行われる追加の操作がバイナリデータのコピーになるということが発生します。:
Bin1 = <<Bin0,...>>,
<<X,Y,Z,T/binary>> = Bin1,
Bin = <<Bin1,...>> %% Bin1はコピーされる
これの理由としては、マッチコンテキストはバイナリデータへの直接のポインタを持っているため、そのまま元のデータを加工してしまうと問題が発生してしまうためです。
プロセスがループデータ[2]_、もしくはプロセス辞書に格納するなどして、シンプルにバイナリを保持している場合には、最終的にはガーベジコレクタがバイナリを縮めていきます。もし、一つだけしかこのようなバイナリを保持していなかったとすると、そのバイナリは縮められることはありません。もしプロセスが縮められたバイナリに対して後で追加するときには、バイナリオブジェクトは追加されるデータのために再割り当てされることになります。
| [2] | (訳注)おそらく、最適化されてループになった後に、そのループ関数内で使用されるデータのこと |
4.3. バイナリのマッチング¶
前の方で紹介したサンプルを再度紹介します。
推奨(R12B):
my_binary_to_list(<<H,T/binary>>) ->
[H|my_binary_to_list(T)];
my_binary_to_list(<<>>) -> [].
それでは、これからフードの下では何が起きているのか、見ていきます。
一番最初に my_binary_to_list/1 が呼ばれると、マッチコンテキストが作成されます。このマッチコンテキストバイナリの最初のバイトを指しています。1バイト目にマッチして、マッチコンテキストはバイナリの2バイト目を次に指すようになります。
R11Bでは、この時点でサブバイナリが作成されていました。R12Bではコンパイラが判断して、サブバイナリは作成されません。このコードでは、これらはすぐに関数(この場合は今いる関数と同じ my_binary_to_list/1 に対して再帰)呼び出しが発生し、すぐに新しいマッチコンテキストが作成され、サブバイナリが無駄になってしまうということが分かるからです。
そのため、R12Bでは my_binary_to_list/1 はサブバイナリではなく、マッチコンテキストを伴って呼び出されます。マッチ操作は、バイナリの代わりにマッチコンテキストが渡された場合には、基本的に何もしないというように初期化されるでしょう。
バイナリの終端に達して、2つめのクロージャがマッチした場合には、マッチコンテキストはそのまま破棄されます。他のものから参照されなくなるため、次のガーベジコレクションで削除されるでしょう。
まとめると、R12Bでは、my_binary_to_list/1では一つのマッチコンテキストが作成され、サブバイナリは作成されません。R11Bでは、バイナリがNバイトあったとすると、N+1個のマッチコンテキストと、N個のサブバイナリが作成されます。
R11Bにおいて、バイナリにマッチさせる、もっとも高速な方法は以下の通りです。
非推奨(R12B):
my_complicated_binary_to_list(Bin) ->
my_complicated_binary_to_list(Bin, 0).
my_complicated_binary_to_list(Bin, Skip) ->
case Bin of
<<_:Skip/binary,Byte,_/binary>> ->
[Byte|my_complicated_binary_to_list(Bin, Skip+1)];
<<_:Skip/binary>> ->
[]
end.
この関数はずるがしこくサブバイナリの作成から逃れています。しかし、再帰一回ごとにマッチコンテキストが1つ作成されてしまうことからは逃げられていません。そのため、R11BとR12Bの両方で、my_complicated_binary_to_list/1はN+1個のマッチコンテキストが作成されてしまいます。将来のリリースではマッチコンテキストを再利用するようなコードを生成できるようになるはずですが、すぐにそうなる、という過度な期待はしないでください。
my_binary_to_list/1に返す場合、バイナリがすべて探索し終わる時にマッチコンテキストが破棄される、ということに注意してください。もしバイナリの終端に達する前にイテレーションが止まったらどうなるでしょうか?それでも最適化は働くのでしょうか?:
After_zero(<<0,T/binary>>) ->
T;
after_zero(<<_,T/binary>>) ->
after_zero(T);
after_zero(<<>>) ->
<<>>.
はい。最適化は働きます。コンパイラは2番目の節内でのサブバイナリの作成を削除します。:
.
.
.
after_zero(<<_,T/binary>>) ->
after_zero(T);
.
.
.
しかし、最初の節ではサブバイナリを作成するコードを生成します。:
after_zero(<<0,T/binary>>) ->
T;
.
.
.
そのため、ゼロバイトのバイナリが渡されたと仮定すると、after_zero/1は一つのマッチコンテキストと、一つのサブバイナリを作成します。
以下のようなコードも最適化されます。:
all_but_zeroes_to_list(Buffer, Acc, 0) ->
{lists:reverse(Acc),Buffer};
all_but_zeroes_to_list(<<0,T/binary>>, Acc, Remaining) ->
all_but_zeroes_to_list(T, Acc, Remaining-1);
all_but_zeroes_to_list(<<Byte,T/binary>>, Acc, Remaining) ->
all_but_zeroes_to_list(T, [Byte|Acc], Remaining-1).
コンパイラは、2番目、3番目の節におけるサブバイナリの作成は削除します。代わりに、最初の節ではBufferをマッチコンテキストからサブバイナリに変換するコードが追加されます。もしBufferがすでにバイナリであれば、何もしません。
そろそろ、どんなバイナリのパターンでもコンパイラが最適化してくれると考えているかもしれませんが、以下の関数は少なくとも現在のバージョンでは最適化が行えません。:
non_opt_eq([H|T1], <<H,T2/binary>>) ->
non_opt_eq(T1, T2);
non_opt_eq([_|_], <<_,_/binary>>) ->
false;
non_opt_eq([], <<>>) ->
true.
前の説明で軽く触れましたが、コンパイラができるのは、バイナリが共有されないというのが明確になっている場合にサブバイナリの作成を遅延させることです。この場合はコンパイラはそれが確認できません。
私たちはサブバイナリ作成を遅延化できるようにnon_opt_eq/2を書き換える方法について、すぐに紹介します。そして、これより重要なのは、コードが最適化されているかどうかはどのように判断すればいいのか、というのを紹介することです。
4.3.1. bin_opt_infoオプション¶
bin_opt_infoオプションを使用することで、バイナリの最適化に関する多くの情報を出力することができます。これはコンパイラとerlc(訳注:erlc以外にコンパイラってあるの?compilerディレクティブ?)にこのオプションを渡すことができます。
erlc +bin_opt_info Mod.erl
また、環境変数として渡すこともできます。
export ERL_COMPILER_OPTIONS=bin_opt_info
このbin_opt_infoはMakefileの中にいつまでも書いておくようなオプションではありません。エラーメッセージなどとは異なり、このオプションが生成するメッセージはすべてなくすということができないからです。そのため、環境変数を通じてオプションを渡すというという方法が、ほとんどのケースで実践的に使われる方法となるでしょう。
警告は以下のように表示されます。
./efficiency_guide.erl:60: Warning: NOT OPTIMIZED: sub binary is used or returned
./efficiency_guide.erl:62: Warning: OPTIMIZED: creation of sub binary delayed
警告がどのコードを参照しているかを見ると、警告の内容が正確に分かるようになります。以下のサンプルでは警告メッセージをコメントとして節の後に挿入しています:
after_zero(<<0,T/binary>>) ->
%% NOT OPTIMIZED: sub binary is used or returned
T;
after_zero(<<_,T/binary>>) ->
%% OPTIMIZED: creation of sub binary delayed
after_zero(T);
after_zero(<<>>) ->
<<>>.
最初の節の警告は、即座に返されるためにサブバイナリの生成を遅延させることができないということを伝えています。二番目の節の警告はサブバイナリの生成がこの場ではまだ行われていないということを伝えています。
最初のサンプルコードに戻って参照してみます。警告を出してみると、コードが最適化されていないということと、どういった理由で最適化されていないかということが分かります。:
non_opt_eq([H|T1], <<H,T2/binary>>) ->
%% INFO: matching anything else but a plain variable to
%% the left of binary pattern will prevent delayed
%% sub binary optimization;
%% SUGGEST changing argument order
%% NOT OPTIMIZED: called function non_opt_eq/2 does not
%% begin with a suitable binary matching instruction
non_opt_eq(T1, T2);
non_opt_eq([_|_], <<_,_/binary>>) ->
false;
non_opt_eq([], <<>>) ->
true.
コンパイラは2種類の警告を出しました。INFO警告はnon_opt_eq/2が呼び出される関数として参照し、non_opt_eq/2をコールするどんな関数であっても、サブバイナリ遅延による最適化が行えないということを示しています。
この警告の中では、引数の順番の変更についても提案されています。二番目の警告(最初の警告と同じ行を参照して発生しています)は、サブバイナリの作成がこの中で行われてしまうということを示しています。
INFOとNOT OPTIMIZED警告が分かりやすく区別できるような他のサンプルコードを見てみましょう。このコードに関しては、引数の順序の変更の提案がされなければならないと思っています。:
opt_eq(<<H,T1/binary>>, [H|T2]) ->
%% OPTIMIZED: creation of sub binary delayed
opt_eq(T1, T2);
opt_eq(<<_,_/binary>>, [_|_]) ->
false;
opt_eq(<<>>, []) ->
true.
以下のコード片に関しては、以下のような警告を生成するでしょう。:
match_body([0|_], <<H,_/binary>>) ->
%% INFO: matching anything else but a plain variable to
%% the left of binary pattern will prevent delayed
%% sub binary optimization;
%% SUGGEST changing argument order
done;
.
.
.
この警告が意味することは、match_body/2の他の節、あるいは他の関数からmatch_body/2の呼び出しがあったとすると、サブバイナリ遅延による最適化が行われないということです。他にも、サブバイナリのマッチが最後に行われる、もしくはmatch_body/2の二番目の引数として渡される場合に表示される警告があります。以下にサンプルを表示します。:
match_head(List, <<_:10,Data/binary>>) ->
%% NOT OPTIMIZED: called function match_body/2 does not
%% begin with a suitable binary matching instruction
match_body(List, Data).
4.3.2. 未使用変数¶
コンパイラは未使用の変数の追跡も行います。以下の3つの関数をコンパイルすると、同じコードが生成されます。:
count1(<<_,T/binary>>, Count) -> count1(T, Count+1);
count1(<<>>, Count) -> Count.
count2(<<H,T/binary>>, Count) -> count2(T, Count+1);
count2(<<>>, Count) -> Count.
count3(<<_H,T/binary>>, Count) -> count3(T, Count+1);
count3(<<>>, Count) -> Count.
それぞれのイテレーションでは、最初の8ビットのバイナリが変数にマッチせずにスキップされます。
Copyright (c) 1991-2009 Ericsson AB